Ingesting Variants
This step describes how to ingest data into VarFish, that is
annotating variants and preparing them for import into VarFish
actually importing them into VarFish.
All of the steps below assume that you are running the Linux operating system. It might also work on Mac OS but is curently unsupported.
Variant Annotation
In order to import a VCF file with SNVs and small indels, the file has to be prepared for import into VarFish server. This is done using the Varfish Annotator software.
Installing the Annotator
The VarFish Annotator is written in Java and you can find the JAR on varfish-annotator Github releases page.
However, it is recommended to install it via bioconda.
For this, you first have to install bioconda as described in their manual.
Please ensure that you have the channels conda-forge, bioconda, and defaults set in the correct order as described in the bioconda installation manual.
A common pitfall is to forget the channel setup and subsequent failure to install varfish-annotator.
The next step is to install the varfish-annotator-cli package or create a conda environment with it.
# EITHER
$ conda install -y varfish-annotator-cli==0.14.0
# OR
$ conda create -y -n varfish-annotator varfish-annotator-cli==0.14.0
$ conda activate varfish-annotator
As a side remark, you might consider installing mamba first and then using mamba install and create in favour of conda install and create.
Obtaining the Annotator Data
The downloaded archive has a size of ~10 GB while the extracted data has a size of ~55 GB.
$ GENOME=grch37 # alternatively use grch38
$ H2_RELEASE=20210728b
$ JV_RELEASE=20210728
$ mkdir varfish-annotator-$RELEASE-$GENOME
$ cd varfish-annotator-$RELEASE-$GENOME
$ wget --no-check-certificate \
https://file-public.cubi.bihealth.org/transient/varfish/anthenea/varfish-annotator-db-$H2_RELEASE-$GENOME.h2.db.gz{,.sha256} \
https://file-public.cubi.bihealth.org/transient/varfish/anthenea/jannovar-db-$JV_RELEASE-$GENOME.tar.gz{,.sha256}
$ sha256sum --check varfish-annotator-db-$H2_RELEASE-$GENOME.h2.db.gz.sha256
varfish-annotator-db-$H2_RELEASE-grch37.h2.db.gz: OK
$ sha256sum --check jannovar-db-$JV_RELEASE-$GENOME.tar.gz.sha256
jannovar-db-$JV_RELEASE-grch37.tar.gz: OK
$ gzip -d varfish-annotator-db-$H2_RELEASE-$GENOME.h2.db.gz
$ tar xf jannovar-db-$JV_RELEASE-$GENOME.tar.gz
$ rm jannovar-db-$JV_RELEASE-$RELEASE.tar.gz{,.sha256} \
varfish-annotator-db-$RELEASE-$GENOME.h2.db.gz.sha256
$ mv jannovar-db-$JV_RELEASE-$GENOME/* .
$ rmdir jannovar-db-$JV_RELEASE-$GENOME
Annotating VCF Files
First, obtain some tests data for annotation and later import into VarFish Server.
# use $GENOME and $RELEASE from above
$ wget --no-check-certificate \
https://file-public.cubi.bihealth.org/transient/varfish/anthenea/varfish-test-data-v1-20211125.tar.gz{,.sha256}
$ sha256sum --check varfish-test-data-v1-20211125.tar.gz.sha256
varfish-test-data-v1-20211125.tar.gz: OK
$ tar -xf varfish-test-data-v1-20211125.tar.gz
varfish-test-data-v1-20211125/
...
varfish-test-data-v1-20211125/GRCh37/vcf/HG00107-N1-DNA1-WES1/bwa.gatk_hc.HG00107-N1-DNA1-WES1.vcf.gz
...
Annotating Small Variant VCFs
Next, you can use the varfish-annotator command.
You must provide an bgzip-compressed VCF file INPUT.vcf.gz
Note
Note that you also have to provide a .fai file next to the reference .fa file.
1# Use the path to the FASTA file that you used for alignment.
2$ REFERENCE=path/to/hs37fa.fa--or--hs38.fa
3# use $GENOME and $RELEASE from above
4$ varfish-annotator \
5 -XX:MaxHeapSize=10g \
6 -XX:+UseConcMarkSweepGC \
7 annotate \
8 --
9
10 ./varfish-annotator-$RELEASE-$GENOME/varfish-annotator-db-$RELEASE-$GENOME.h2.db \
11 --ensembl-ser-path varfish-annotator-$RELEASE-$GENOME/ensembl*.ser \
12 --refseq-ser-path varfish-annotator-$RELEASE-$GENOME/refseq_curated*.ser \
13 --ref-path $REFERENCE \
14 --input-vcf "INPUT.vcf.gz" \
15 --release "$GENOME" \
16 --output-db-info "FAM_name.db-infos.tsv" \
17 --output-gts "FAM_name.gts.tsv" \
18 --case-id "FAM_name"
Let us disect this call.
The first three lines contain the code to the wrapper script and some arguments for the java binary to allow for enough memory when running.
1$ varfish-annotator \
2 -XX:MaxHeapSize=10g \
3 -XX:+UseConcMarkSweepGC \
The next lines use the annotate sub command and provide the needed paths to the database files needed for annotation.
The .h2.db file contains information from variant databases such as gnomAD and ClinVar.
The .ser file are transcript databases used by the Jannovar library.
The .fa file is the path to the genome reference file used.
While only release GRCh37/hg19 is supported, using a file with UCSC-style chromosome names having chr prefixes would also work.
4 --db-path ./varfish-annotator-$RELEASE-$GENOME/varfish-annotator-db-$RELEASE-$GENOME.h2.db \
5 --ensembl-ser-path varfish-annotator-$RELEASE-$GENOME/ensembl*.ser \
6 --refseq-ser-path varfish-annotator-$RELEASE-$GENOME/refseq_curated*.ser \
7 --ref-path $REFERENCE \
The following lines provide the path to the input VCF file, specify the release name (must be GRCh37) and the name of the case as written out.
This could be the name of the index patient, for example.
9 --input-vcf "INPUT.vcf.gz" \
10 --release "GRCh37" \
11 --case-id "index" \
The last lines
12 --output-db-info "FAM_name.db-info.tsv" \
13 --output-gts "FAM_name.gts.tsv"
After the program terminates, you should create gzip files for the created TSV files and md5 sum files for them.
$ gzip -c FAM_name.db-info.tsv >FAM_name.db-info.tsv.gz
$ md5sum FAM_name.db-info.tsv.gz >FAM_name.db-info.tsv.gz.md5
$ gzip -c FAM_name.gts.tsv >FAM_name.gts.tsv.gz
$ md5sum FAM_name.gts.tsv.gz >FAM_name.gts.tsv.gz.md5
The next step is to import these files into VarFish server. For this, a PLINK PED file has to be provided. This is a tab-separated values (TSV) file with the following columns:
family name
individul name
father name or
0for foundermother name or
0for foundersex of individual,
1for male,2for female,0if unknowndisease state of individual,
1for unaffected,2for affected,0if unknown
For example, a trio would look as follows:
FAM_index index father mother 2 2
FAM_index father 0 0 1 1
FAM_index mother 0 0 2 1
while a singleton could look as follows:
FAM_index index 0 0 2 1
Note that you have to link family individuals with pseudo entries that have no corresponding entry in the VCF file. For example, if you have genotypes for two siblings but none for the parents:
FAM_index sister father mother 2 2
FAM_index broth father mother 2 2
FAM_index father 0 0 1 1
FAM_index mother 0 0 2 1
Annotating Structural Variant VCFs
Structural variants can be annotated as follows.
1# use $GENOME from above
2$ varfish-annotator \
3 annotate-svs \
4 -XX:MaxHeapSize=10g \
5 -XX:+UseConcMarkSweepGC \
6 \
7 --default-sv-method=YOURCALLERvVERSION"
8 --release $GENOME \
9 \
10 --db-path ./varfish-annotator-$RELEASE-$GENOME/varfish-annotator-db-$RELEASE-$GENOME.h2.db \
11 --ensembl-ser-path varfish-annotator-$RELEASE-$GENOME/ensembl*.ser \
12 --refseq-ser-path varfish-annotator-$RELEASE-$GENOME/refseq_curated*.ser \
13 \
14 --input-vcf FAM_sv_calls.vcf.gz \
15 --output-db-info FAM_sv_calls.db-info.tsv \
16 --output-gts FAM_sv_calls.gts.tsv
17 --output-feature-effects CASE_SV_CALLS.feature-effects.tsv
Note
varfish-annotator annotate-svs will write out the INFO/SVMETHOD column to the output file.
If this value is empty then the value from --default-sv-method will be used.
You must either provide INFO/SVMETHOD or --default-sv-method.
Otherwise, you will get errors in the import step (visible in the case import background task view).
You can use the following shell snippet for adding INFO/SVMETHOD to your VCF file properly.
Replace YOURCALLERvVERSION with the value that you want to provide to Varfish.
cat >$TMPDIR/header.txt <<"EOF"
##INFO=<ID=SVMETHOD,Number=1,Type=String,Description="Type of approach used to detect SV">
EOF
bcftools annotate \
--header-lines $TMPDIR/header.txt \
INPUT.vcf.gz \
| awk -F $'\t' '
BEGIN { OFS = FS; }
/^#/ { print $0; }
/^[^#]/ { $8 = $8 ";SVMETHOD=YOURCALLERvVERSION"; print $0; }
' \
| bgzip -c \
> OUTPUT.vcf.gz
tabix -f OUTPUT.vcf.gz
Again, you have have to compress the output TSV files with gzip and compute MD5 sums.
$ gzip -c FAM_sv_calls.db-info.tsv >FAM_sv_calls.db-info.tsv.gz
$ md5sum FAM_sv_calls.db-info.tsv.gz >FAM_sv_calls.db-info.tsv.gz.md5
$ gzip -c FAM_sv_calls.gts.tsv >FAM_sv_calls.gts.tsv.gz
$ md5sum FAM_sv_calls.gts.tsv.gz >FAM_sv_calls.gts.tsv.gz.md5
$ gzip -c FAM_sv_calls.feature-effects.tsv >FAM_sv_calls.feature-effects.tsv.gz
$ md5sum FAM_sv_calls.feature-effects.tsv.gz >FAM_sv_calls.feature-effectstsv.gz.md5
Variant Import
As a prerequisite you need to install the VarFish command line interface (CLI) Python app varfish-cli.
You can install it from PyPi with pip install varfish-cli or from Bioconda with conda install varfish-cli.
Second, you need to create a new API token as described in API Token Management.
Then, setup your Varfish CLI configuration file ~/.varfishrc.toml as:
[global]
varfish_server_url = "https://varfish.example.com/"
varfish_api_token = "XXX"
Now you can import the data that you imported above.
You will also find some example files in the test-data directory.
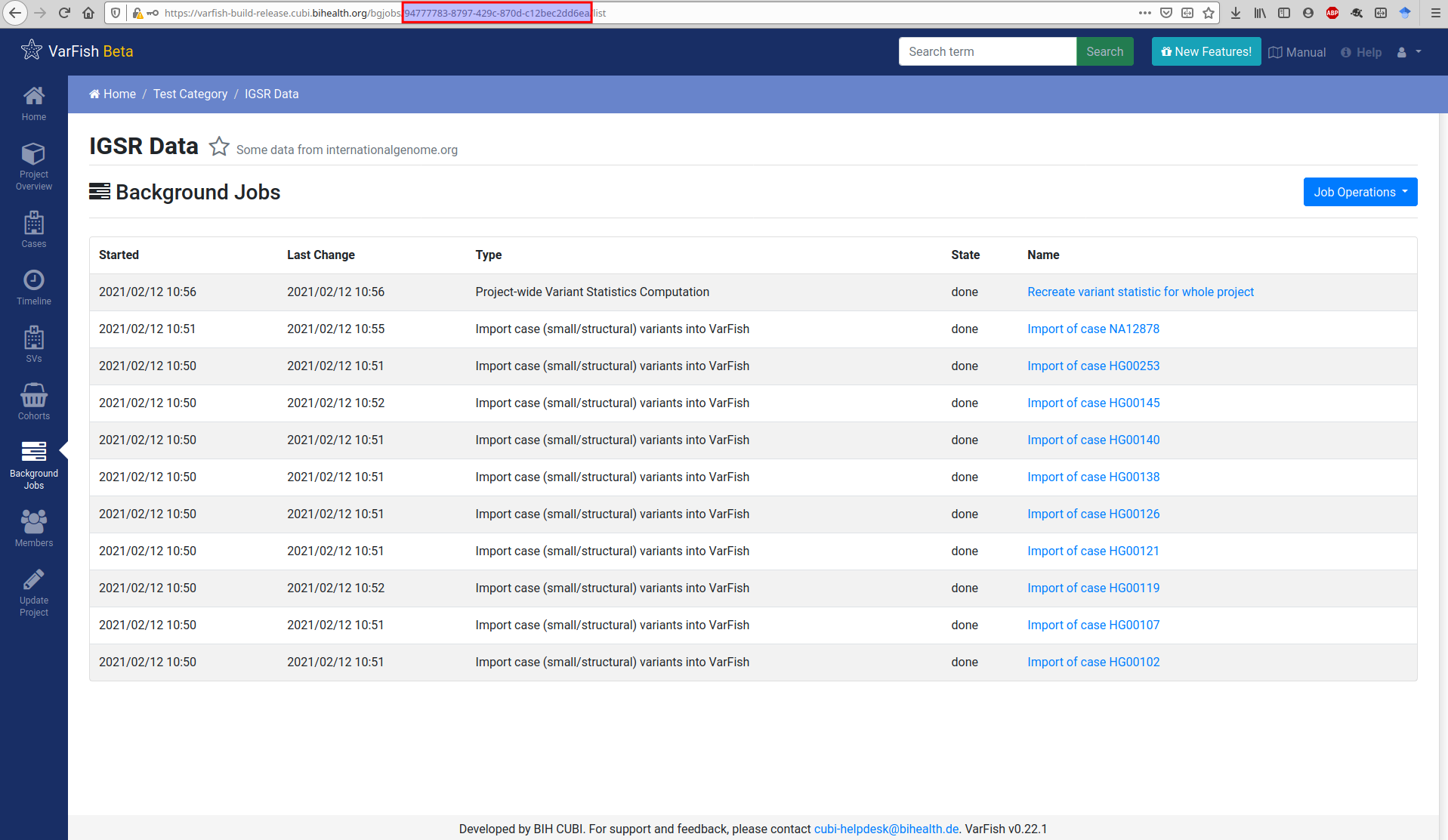
For the import you will also need the project UUID. You can get this from the URLs in VarFish that list project properties. The figure below shows this for the background job list but this also works for the project details view.
$ varfish-cli --no-verify-ssl case create-import-info --resubmit \
94777783-8797-429c-870d-c12bec2dd6ea \
test-data/tsv/HG00102-N1-DNA1-WES1/*.{tsv.gz,.ped}
When executing the import as shown above, you have to specify:
a pedigree file with suffix
.ped,a genotype annotation file as generated by
varfish-annotatorending in.gts.tsv.gz,a database info file as generated by
varfish-annotatorending in.db-info.tsv.gz.
Optionally, you can also specify a TSV file with BAM quality control metris ending in .bam-qc.tsv.gz.
Currently, the format is not properly documented yet but documentation and supporting tools are forthcoming.
If you want to import structural variants for your case, then you simply submit the output files from the SV annotation step together with the the .feature-effects.tsv.gz and .gts.tsv.gz files from the small variant annotation step.
Running the import command through VarFish CLI will create a background import job as shown below. Once the job is done, the created or updated case will appear in the case list.
Case Quality Control
You can provide an optional TSV file with case quality control data.
The file name should end in .bam-qc.tsv.gz and also accompanied with a MD5 file.
The format is a bit peculiar and will be documented better in the future.
The TSV file has three columns and starts with the header.
case_id set_id bam_stats
It is then followed by exactly one line where the first two fields have to have the value of a dot (.).
The last row is then a PostgreSQL-encoded JSON dict with the per-sample quality control information.
You can obtain the PostgreSQL-encoding by replacing all string delimiters (") with three ones (""""`).
The format of the JSON file is formally defined in api_json_schemas_case_qc_v1.
Briefly, the keys of the top level dict are the sample names as in the case that you upload. On the second level:
bamstatsThe keys/values from the output of the
samtools statscommand.min_cov_targetCoverage histogram per target (the smallest coverage per target/exon counts for the whole target). You provide the start of each bin, usually starting at
"0", in increments of 10, up to"200". The keys are the bin lower bounds, the values are of JSON/JavaScriptnumbertype, so floating point numbers.min_cov_baseThe same information as
min_cov_targetbut considering coverage base-wise and not target-wise.summaryA summary of the target information.
idxstatsA per-chromosome count of mapped and unmapped reads as returned by the
samtools idxstatscommand.
You can find the example of a real-world JSON QC file below for the first sample.